
[DZONE] How a stream works?
A stream is a sequence of elements. An array is a data structure that stores a sequence of values. Then, a stream is an array? Well, not really - let’s look at what a stream really is and see how it works.
First of all, streams don’t store elements, an array does. So, no, a stream is not an array. Also, while collections and arrays have a finite size, streams don’t. But, if a stream doesn’t store elements, how can it be a sequence of elements?
Streams are actually a sequence of data being moved from one point to the another, but they’re computed on demand. So, they have at least one source, like arrays, lists, I/O resources, and so on. Let’s take a file for an example: when a file is opened for editing, all or part of it remains in memory, thus allowing for changes, so only when it is closed there’s a guarantee that no data will be lost or damaged.
Fortunately, a stream can read/write data chunk by chunk, without buffering the whole file at once. Just so you know, a buffer is a region of a physical memory storage (usually RAM) used to temporarily store data while it is being moved from one place to another.
Node.js has four stream types and that are worthy of mentioning:
- Writable - streams to which data can be written (for example, writing to a file, sending HTTP request/response).
- Readable - streams from which data can be read (for example reading from a file, receiving HTTP request/response).
- Duplex - streams that are both Readable and Writable (for example, a TCP socket).
- Transform - Duplex streams that can modify or transform the data as it is written and read it (for example, a zlib compression file).
Functions that operate on a stream and produce another stream are known as filters and can be connected in pipelines, like below:
Arrays.asList(10,3,13,4,1,52)
.stream()
.filter(number -> number % 2 == 0) //10,4,52
.sorted() //4,10,52
.skip(1) //10,52
.forEach(System.out::println); //prints 10 and prints 52
When it comes to Java Streams, what is interesting is that they provide lazy evaluation. The Javadoc says:
Stream operations are divided into intermediate ( Stream-producing) operations and terminal (value- or side-effect-producing) operations. Intermediate operations are always lazy.
So, if I do this:
List<Integer> numbers = Arrays.asList(10,3,13,4,1,52);
Stream<Integer> numberStream = numbers.stream()
.filter(number -> number % 2 == 0) //10,4,52
.sorted() //4,10,52
.skip(1) //10,52
.peek(System.out::println); //used to execute something while stream is processing
The stream is not executed yet, because it is smart enough to wait for a terminal operation to be called, like forEach, reduce, anyMatch, and so on. In addition to having declarative style, it is also smart enough to stop as soon as the terminal operation is met. For example:
Integer integer = Arrays.asList(10,3,13,4,1,52)
.stream()
.filter(number -> number % 2 == 0)
.sorted()
.skip(1)
.peek(System.out::println) //it prints only 10 instead of 10 and 52
.findFirst().get();
Because of sorted() on the above stream, the filter method will run on the whole stream, but skip doesn’t run on the whole filtered and sorted stream. Let’s see this example:
Integer integer = Arrays.asList(10,3,13,4,1,52)
.stream()
.filter(number -> number % 2 == 0)
.findFirst().get();

Some might think that filter would run on every element and then find first, but as I said: the Java stream is smart enough.
Another interesting thing about Java Streams is parallel streams:
Arrays.asList(10,3,13,4,1,52,2,6,8)
.parallelStream()
.filter(number -> number % 2 == 0)
.forEach(number -> System.out.println(Thread.currentThread())); //prints which thread is being executed
When a stream executes in parallel, the Java runtime partitions the stream into multiple substreams. Aggregate operations iterate over and process these substreams in parallel and then combine the results.

Now that you know the concepts of how streams work, let’s look at some tools.
Apache Kafka
Kafka is a distributed streaming platform that has three key capabilities:
- Publish and subscribe to streams of records, similar to a message queue or enterprise messaging system.
- Store streams of records in a fault-tolerant, durable way.
- Process streams of records as they occur.
The purpose is to enable real-time processing of streams and it supports many data sources using Kafka Connect (such as JDBC, ActiveMQ, REST API, and others). Some use cases are: Messaging, Website Activity Tracking, Metrics, Log Aggregation, Stream Processing, Event Sourcing, and Commit Logs.
Here is the anatomy of an application that uses the Kafka Streams API. It provides a logical view of a Kafka Streams application that contains multiple stream threads, that each contain multiple stream tasks.

Amazon Kinesis
Amazon Kinesis is the fully managed Amazon Web Service (AWS) offering for collecting, processing, and analyzing video and data streams in real time. Amazon shows four capabilities:
-
Kinesis Video Streams - Capture, process, and store video streams.
-
Kinesis Data Streams - Capture, process, and store data streams.
-
Kinesis Data Firehose - Load data streams into AWS data stores.
-
Kinesis Data Analytics - Analyze data streams with standard SQL.
The purpose is also to enable real-time processing of streams and some use cases: build video analytics applications, evolve from batch to real-time analytics, build real-time applications, and analyze IoT device data.
Here is how Kinesis Data Streams usually works:
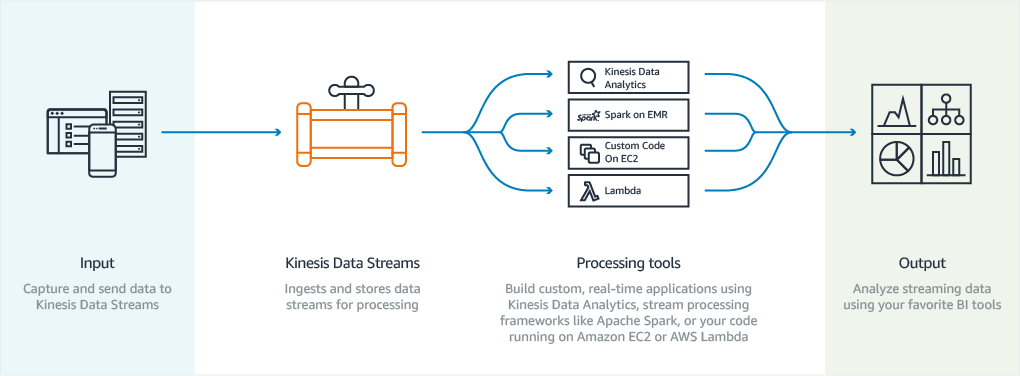
Summarizing
That’s how stream works. We saw a little bit about Node.js streams and Java Streams and tools like Apache Kafka and Amazon Kinesis, plus an overview of each tool. That’s it, I hope you liked it.
- Posted first on: https://dzone.com/articles/how-a-stream-works